머신러닝 모델에서 SVM(Support Vector Machine)이 무엇인지, 어떻게 작동하는지, Maximum Margin과 Soft Margin의 차이점은 무엇인지 알아보겠습니다. 또한 scikit-learn 라이브러리를 사용하여 지원 벡터 머신 커널 트릭과 코드 예제를 살펴봅니다.
서포트 벡터 머신 모델이란 무엇입니까?
SVM(Support Vector Machine) 모델은 선형 또는 비선형 분류, 회귀 및 이상값 감지에 사용할 수 있는 강력하고 다양한 기계 학습 모델입니다. 그래서 가장 널리 사용되는 모델 중 하나입니다.서포트 벡터 머신의 목표는 N 차원에 분산된 서로 다른 데이터 세트를 분할하기 위한 초평면 찾기보지 않았다. 이 말만 들으면 이해하지 못할 것이다. 서포트 벡터 머신 모델이 작동하는 방식을 이해하는 데 필요한 개념을 소개합니다.이 모델을 배우기 전에 선형 회귀수업 로지스틱 회귀이해할 수 있다면 더욱 좋습니다.
최대 증거금 분류
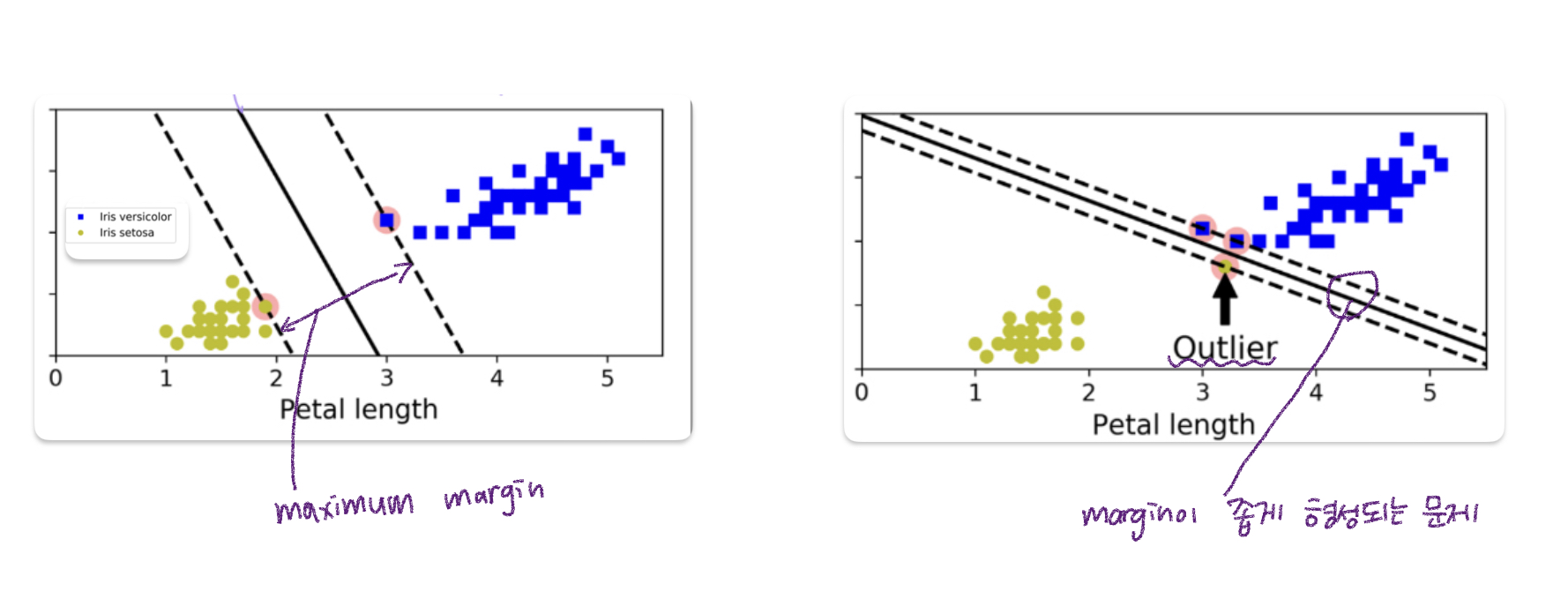
Maximum Margin Classification의 개념을 Iris Data와 함께 설명하여 보다 쉽게 이해할 수 있도록 하겠습니다. Vesicolor 종과 다른 붓꽃 종 Setosa는 꽃잎 너비와 꽃잎 길이의 분포에서 아래와 같이 유의미한 차이를 보였다. 이 두 종을 분류하기 위해 결정 경계를 그릴 때 두 데이터 그룹을 구분하는 선을 그리는 방법은 다양하며, 최대 증거금 분류그것은 알려져있다. 서로 다른 그룹의 데이터가 잘 분산되어 있고 분할하기 쉬운 경우 이 최대 마진 분류기를 사용하여 분류하는 것이 가장 좋습니다. 이 방법을 사용하면 데이터에 이상치가 많고 노이즈가 많은 경우 마진이 매우 좁아질 수 있습니다.보지 않았다. 이를 해결하기 위해 소프트 마진 분류가 아래에 설명되어 있습니다.
소프트 마진 분류
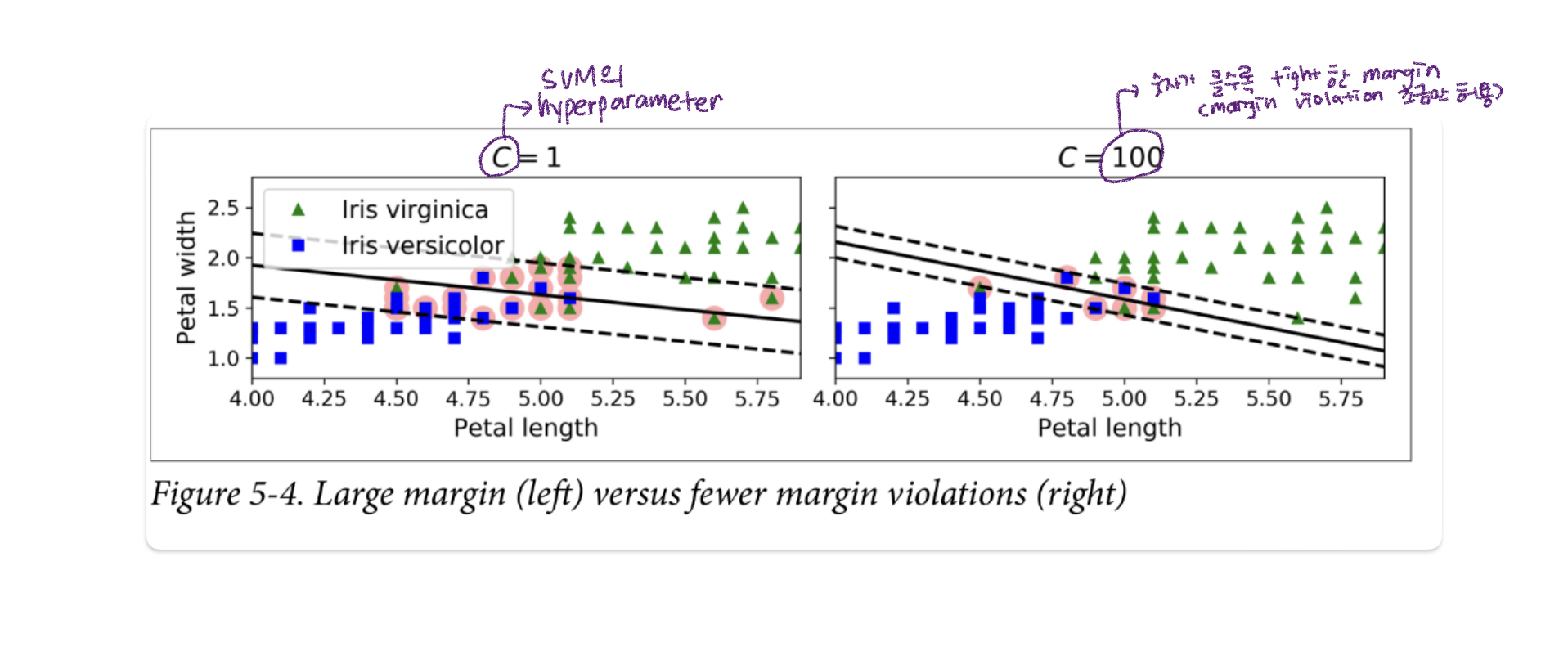
소프트 마진 분류는 일부 오분류가 있는 경우에도 보다 일반적인 결정 경계를 찾는 방법보지 않았다. 위에서 우리는 이상치가 존재하는 상황에서 최대 마진 분류 방법을 사용할 때 마진이 너무 작게 형성되어 일반화가 제대로 이루어지지 않는 것을 보았습니다. 이 경우 이 방법을 해결 방법으로 사용할 수 있습니다. Scikit-learn으로 SVM 모델을 생성할 때 하이퍼파라미터 설정을 통해 오분류 허용 정도를 제어할 수 있습니다.
지원 벡터란 무엇입니까? (지원 벡터)
그렇다면 SVM에서 “지원 벡터”는 무엇을 의미합니까?위의 예에서 지원 벡터는 다음과 같습니다. 결정 경계에 가장 가까운 데이터 포인트의사결정 경계가 어디에 있는지를 결정하는 데 중요한 역할을 한다고 들었다.
비선형 분류 문제
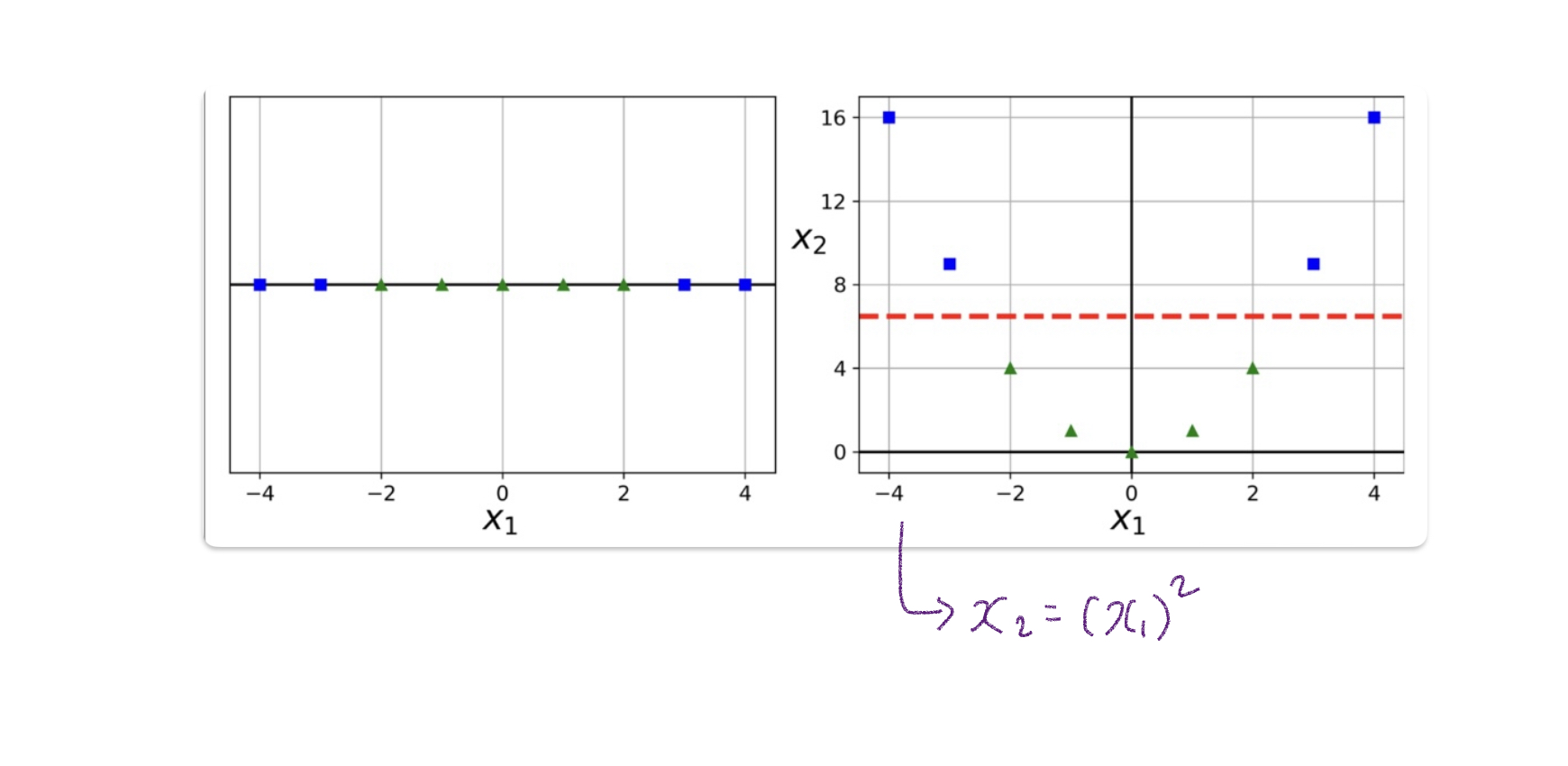
위에서 살펴본 데이터는 선형 분리 가능한 데이터입니다.하지만 실제 데이터그렇게 쉽게 분리되지 않는 대부분의 비선형 데이터보지 않았다. 이 경우 서로 다른 데이터 세트를 구분하는 초평면을 찾는 것이 다항식의 적용입니다. 아래 그림과 같이 1차원 데이터 x1이 있고 두 그룹의 데이터를 직선으로 나누기가 어렵고 비선형 분류가 필요합니다. 이때 이를 2차원 형태로 바꾸어 x2 = (x1)^2로 변환하면 아래 그림과 같은 선형 초평면을 찾을 수 있다.
서포트 벡터 머신을 위한 커널 요령
위의 개념을 사용하여 데이터를 계속해서 더 높은 차원으로 변환하면 비선형 데이터도 분류할 수 있습니다. 데이터를 더 높은 차원으로 변환하고 초평면을 찾으려면 복잡한 계산이 필요합니다. 일이다. SVM은 각 차원에 대한 증가를 계산하지 않습니다. 커널 트릭을 사용한 내적 사용하다. 커널 트릭은 저차원 데이터 포인트를 입력 및 출력 해당 고차원 데이터 포인트로 사용합니다. 예를 들어 보겠습니다.
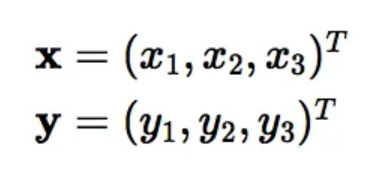
위와 같은 저차원(3차원) 데이터가 있고 이를 9차원 데이터로 변환하고자 한다면 다음과 같은 과정을 거쳐야 합니다.
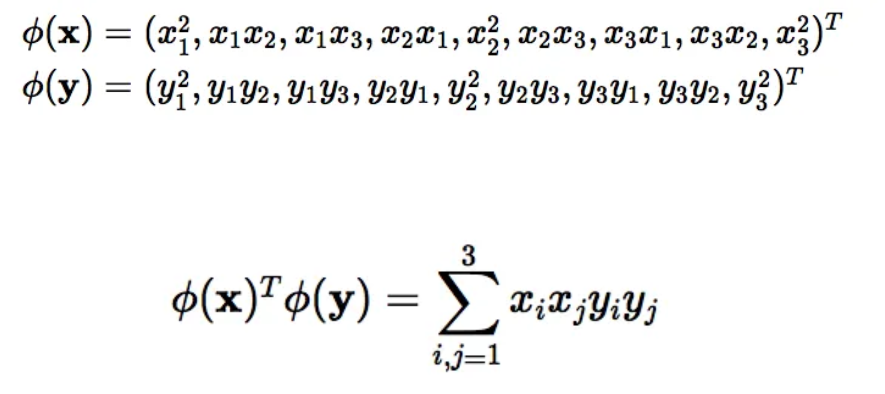
이 프로세스에는 복잡한 계산이 필요합니다. 그러나 이렇게 얻은 결과는 아래 그림에서 X를 전치하여 y와 내적을 구한 결과와 같다. 커널 트릭은 아래와 같이 내적 최소화 계산을 사용하는 것입니다.
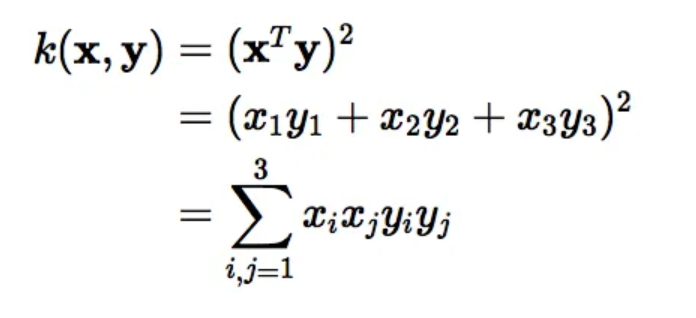
이 커널 트릭은 SVM 모델의 계산을 훨씬 빠르게 만듭니다.
서포트 벡터 머신의 커널 유형다음과 같이 여러 종류가 있는데 Scikit-Learn을 사용할 때 하이퍼파라미터를 통해 커널 종류를 설정할 수 있다.
- 다항식 커널
- 가우시안 커널
- 방사형 기저함수(RBF)
- 라플라스 방사형 기초 함수 커널
- 시그모이드 커널
- Anove RBF 커널
Scikit-learn을 사용한 SVM(Support Vector Machine) 기계 학습 코딩
아래 예는 Scikit-Learn 패키지를 사용하여 Iris 데이터 분류 지원 벡터 머신 모델의 적용을 보여줍니다. 다음은 지원 벡터 머신 모델이 데이터를 분할하는 방법에 대한 결정 경계를 그리는 예입니다.
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
# Load the iris dataset
iris = datasets.load_iris()
# Take only the first two features for visualization
X = iris.data(:, :2)
y = iris.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# Train an SVM model with a radial basis function (RBF) kernel
clf = svm.SVC(kernel="rbf", C=1, gamma="scale")
clf.fit(X_train, y_train)
# Make predictions on the testing set
y_pred = clf.predict(X_test)
# Evaluate the model's performance
accuracy = clf.score(X_test, y_test)
print('Accuracy: {:.2f}'.format(accuracy))# Create a meshgrid of points to plot the decision boundary
xx, yy = np.meshgrid(np.arange(X(:, 0).min() - 0.5, X(:, 0).max() + 0.5, 0.02),
np.arange(X(:, 1).min() - 0.5, X(:, 1).max() + 0.5, 0.02))
Z = clf.predict(np.c_(xx.ravel(), yy.ravel()))
Z = Z.reshape(xx.shape)
# Plot the decision boundary
plt.contourf(xx, yy, Z, cmap=plt.cm.Accent, alpha=0.8)
# Plot the training points
plt.scatter(X_train(:, 0), X_train(:, 1), c=y_train, cmap=plt.cm.Accent)
# Set the plot limits and labels
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('SVM Classifier with RBF Kernel')
plt.show()
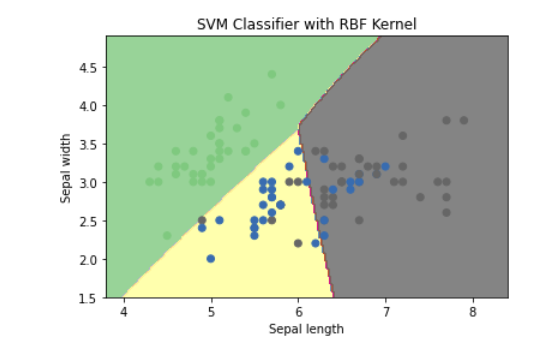
Support Vector Machine은 비선형 데이터도 분류할 수 있기 때문에 다양한 상황에서 가장 많이 사용되는 모델 중 하나입니다. 서포트 벡터 머신 모델을 이해하려면 Maximum margin과 Soft margin의 차이점, 각각의 장점과 단점, 각 하이퍼파라미터의 의미와 Scikit-learn으로 코딩할 때 이를 변경하는 방법을 알아보세요. 무엇을 사용하고 있는지 알아야 합니다. 오늘 포스트에서는 코드 예제와 서포트 벡터 머신의 개념에 대해 살펴보았습니다. 이것이 SVM(Support Vector Machine)을 이해하는 데 도움이 되기를 바랍니다.
(좋은 글은 참고하시면 됩니다)
코드 없는 기계 학습 도구 WEKA(Machine Learning without coding) 사용 방법 코딩 방법을 몰라도 머신러닝을 할 수 있는 방법은 많습니다. 잘 만들어진 GUI 도구를 사용하는 것입니다. 데이터를 로드하고, 수십 개의 기계 학습 모델을 적용하고, 성능을 평가하고, 결과를 평가하십시오. www.datasciencediary.
분류 결정 트리 개념 – 정보 획득, 불순물 및 엔트로피 이해 Decision Tree는 마지막 리프 노드에서 카테고리가 구분되도록 분류를 위한 트리를 그리는 모델입니다. 분류가 결정되는 방법을 검사하는 것은 직관적이고 간단합니다. www.datasciencediary.